Scrape or API? StackOverflow Got Me Thinking...
Learn How To Reverse Engineer Private APIs and Forget About The Old Fashioned Web Scraping

Tech Enthusiast, Self Taught Programmer, Entrepreneur and NGO Leader
Every now and then I go on Stack Overflow and look at interesting questions and sometimes post a comment with my two cents on the topic. Today was one of those days. I landed on THIS question:
How to scrape all the prices data with scrapy
I'm trying to scrape the info from www.kimovil.com and I have one issue with the prices. I want to
scrapyonly this price...
Scraping The Web Using Private APIs
If it weren't for HTTP, the internet as we know it today would have probably been much more difficult to use (or not... I'm just assuming). HTTP makes it so that data is being transfer from servers to clients, at a client's request. The HTTP protocol has security features that can prevent unauthorised access, however, many web applications rely more on aspects and functionality, and less on security. So there's no surprise that some resources can be accessed by anyone on the web.
With that in mind, when I think about web scraping today, I tend to first explore the web app and discover what requests are made and how I can replicate them. It pays off because instead of analysing an entire HTML document with all its tags in order to find and strip some data, requests usually deliver the same data in a nice, json format.
Another way of dealing with web scraping (and without having to build a web scraper from scratch) is to use a third party app. For instance Web Scraping API offers such a solution. The API is not only capable of extracting the raw HTML, but can also parse it and return data in a JSON format.
So coming back to our Stack Overflow question, I discovered that the website mentioned does indeed have an exposed endpoint and so I suggested the owner of the question to make use of it. And here is how I did it:
Discovering Exposed API Endpoints
There are mainly two ways to discover what requests are being made by the web app:
First, is to use the developer options -> Network panel that most Web Browser offer today. A personal discovery is that web apps that don't display many ads or have other types of integrations can be easily analysed using this method.
Second, is to use a proxy tool. My favourite tool in that regard is OWASP ZAP. I use it for apps that do integrate with other platforms which tend to make a lot of requests. Using such a tool facilitates a structure of the requests. Also, I find it easier to navigate between the history.
Taking kimovil.com (the targeted website) as an example, here is how reverse engineering the requests would look like in both cases:
Chrome Developer Tools
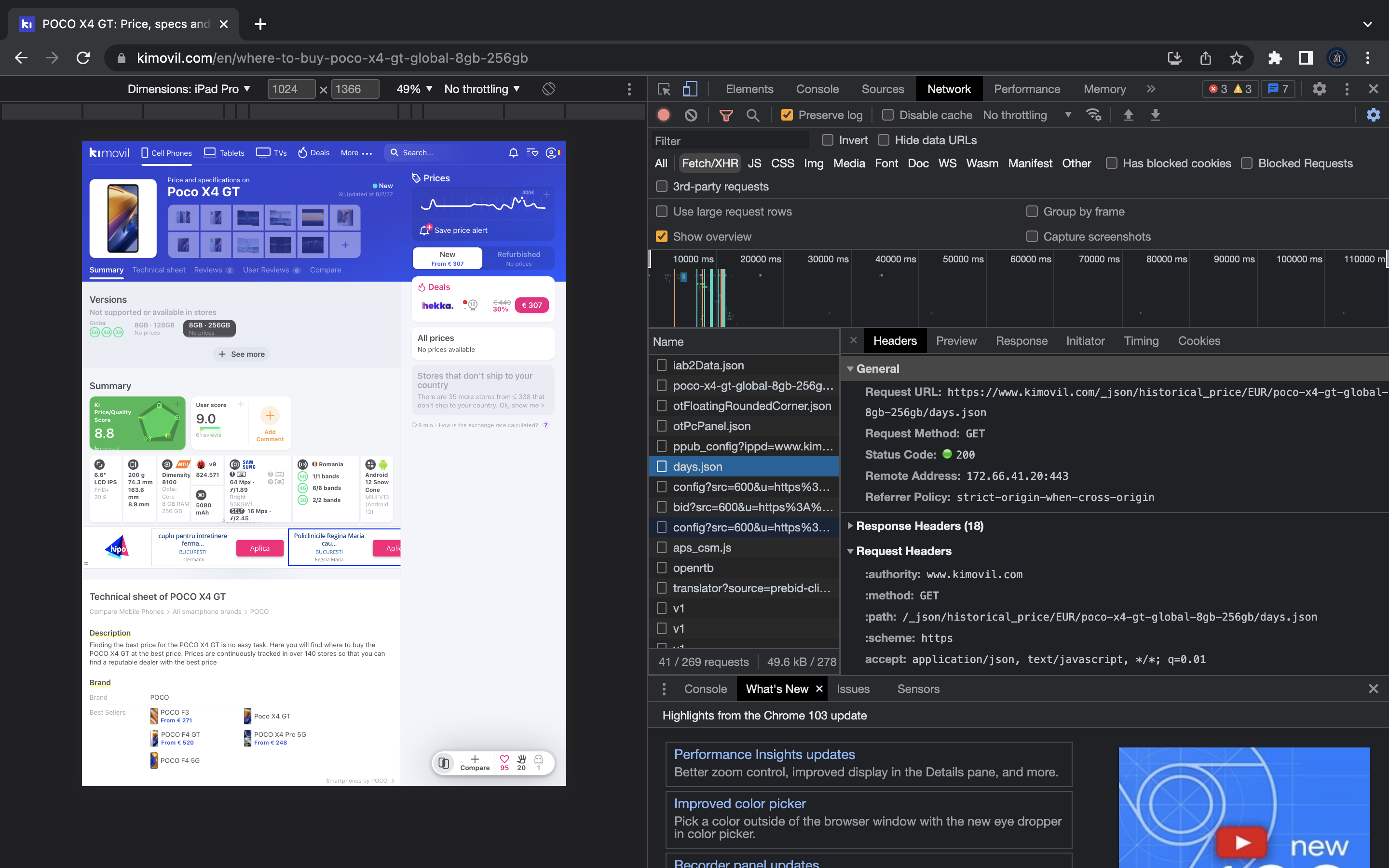
Small tip: Click on the small
Fetch/XHRbutton to better filter the requests.OWASP ZAP
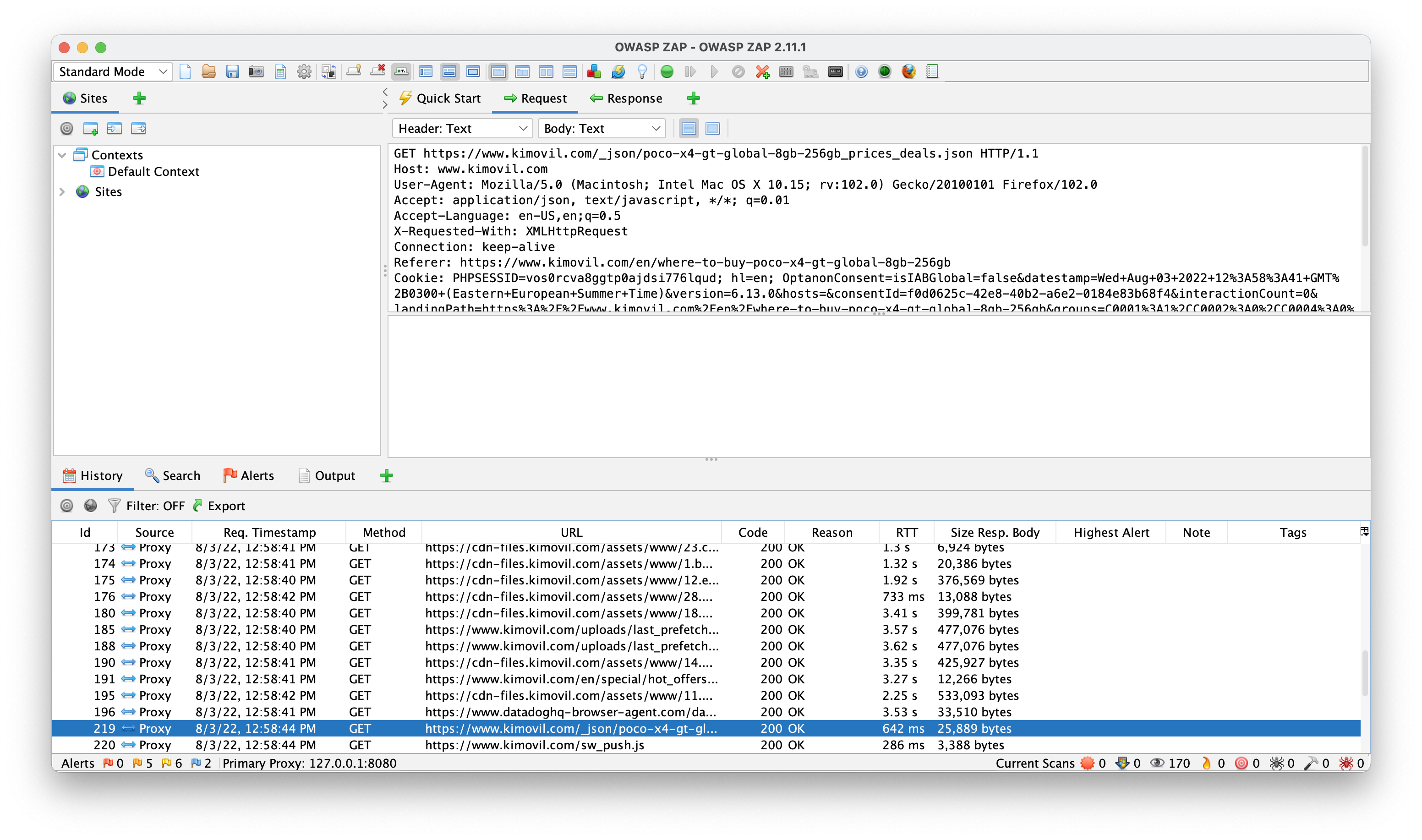
I don't know if it's just me, but I like OWASP ZAP better and it actually helped me spot the exposed endpoint in less than 1 minute. In case you don't see it, it is the
/_json/<phone-model-and-name>_prices_deals.json.
Testing the Endpoint With cURL
Once I find the endpoint, I usually like to test it using cURL just to make sure it is exposed. Sometimes, you might not get the result from the very beginning and you might need to add more data to the request (such as headers or cookies, which is very easy as well - so don't panic).
To do so, we simply run the command in our terminal:
curl -x http://free:<PROXY_PASS>@free.proxyshare.io:80 https://www.kimovil.com/_json/<phone-model-and-name>_prices_deals.json
Notice I used Free Rotating IPs from ProxyShare.io. Using proxies is usually recommended in web scraping.
Back to results. It returns a json object which looks like this:
{
"prices":[
{
"device_id":10999,
"id":2193117,
"originalPrice":"628.17",
"originalCurrency":"EUR",
"shortHash":"https:\/\/www.kimovil.com\/to\/XFF8R3",
"hash":"XFF8R3",
"provider":{
"id":522,
"provider_group_id":525,
"countryDeliveryTo":{
"countryCode":"XX"
},
"destinationCountries":[
"US",
"RU",
"BR",
"CO",
"PE",
"MX"
],
"country_sale_restriction":[
"BR",
"MX",
"RU",
"PE"
],
"warehouse_country_code":"CN"
},
"eurPrice":"628.17",
"gbpPrice":"525.89",
"usdPrice":"644.81",
"rubPrice":"41659.90",
"inrPrice":"50897.95",
"plnPrice":"2962.73",
"brlPrice":"3342.91",
"mxnPrice":"13142.91"
},...
Automate it With Python
Now it’s all a mater of automating the task. You may chose any programming language in that regard, but I like Python for its clean syntax. It only takes two imports and three lines of code to achieve our desired result:
import requests
import re
PHONE_MODEL = 'realme GT 2 Pro'
response = requests.get('https://www.kimovil.com/_json/{}_prices_deals.json'.format(re.sub("\s", "-", PHONE_MODEL.lower())))
print(response.text)
We’re defining a variable that holds the product’s name
We’re sending a
getrequest at the constructed URLWe’re printing the results in our console
Note that we’re formatting the URL using re to replace the spaces with a hyphen and we’re changing the PHONE_MODEL variable to lowercase.
Conclusions
Traditional web scraping comes in handy for data gathering, but is it worth it to follow this aproach from the beginning?
I would say that a little ‘reverse engineering’ has the potential to save you a lot of respurces and it only costs a little extra time to check for exposed endpoints.
Of course, this was just a simple and easy example and in most cases there is some sort of protection (at least by authentication) in place. However, the principle is the same. Most of the time, the only thing that differs is that you have to pass some headers to your request (cookies, tokens etc.).
But don’t stress too much about it, just look at the original request (the one made with the proxy or in your browser) and try to recreate it. Also, you can make multiple requests in your browser or proxy just to see how it behaves and compare results.

![[Vulnerability Report] Redis Unauthenticated Access](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1684485847855%2Fe8b06d55-8e80-4b50-8b44-d5d09d538d07.gif&w=3840&q=75)


